Ingestion
Pipeline setup is a three step process:
- Ingestion configuration
- Dedupe and Scheduling
- Destination setup
Start with adding a new dataset:
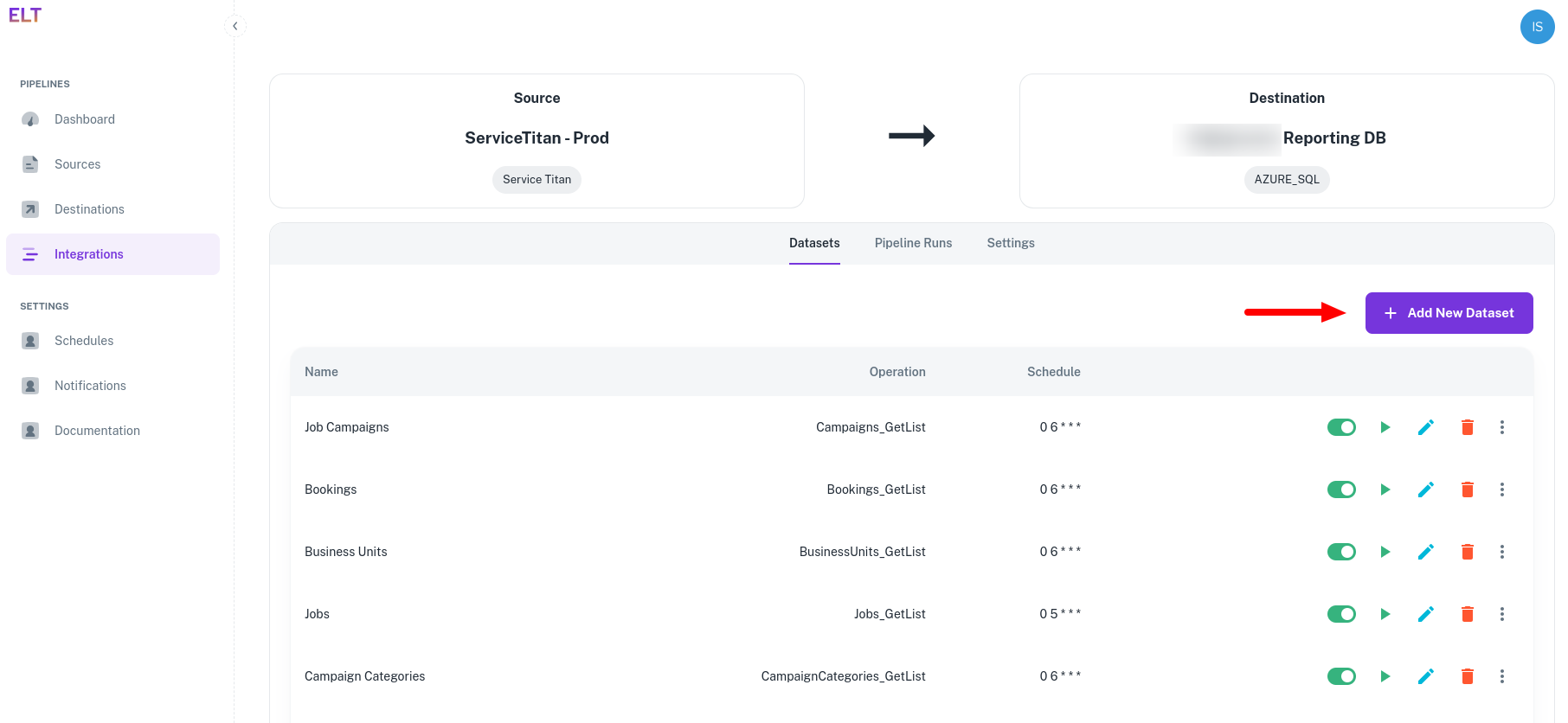
Ingestion configuration
Based on the ingestion source type (Email or API) ELT Data has different configuration options:
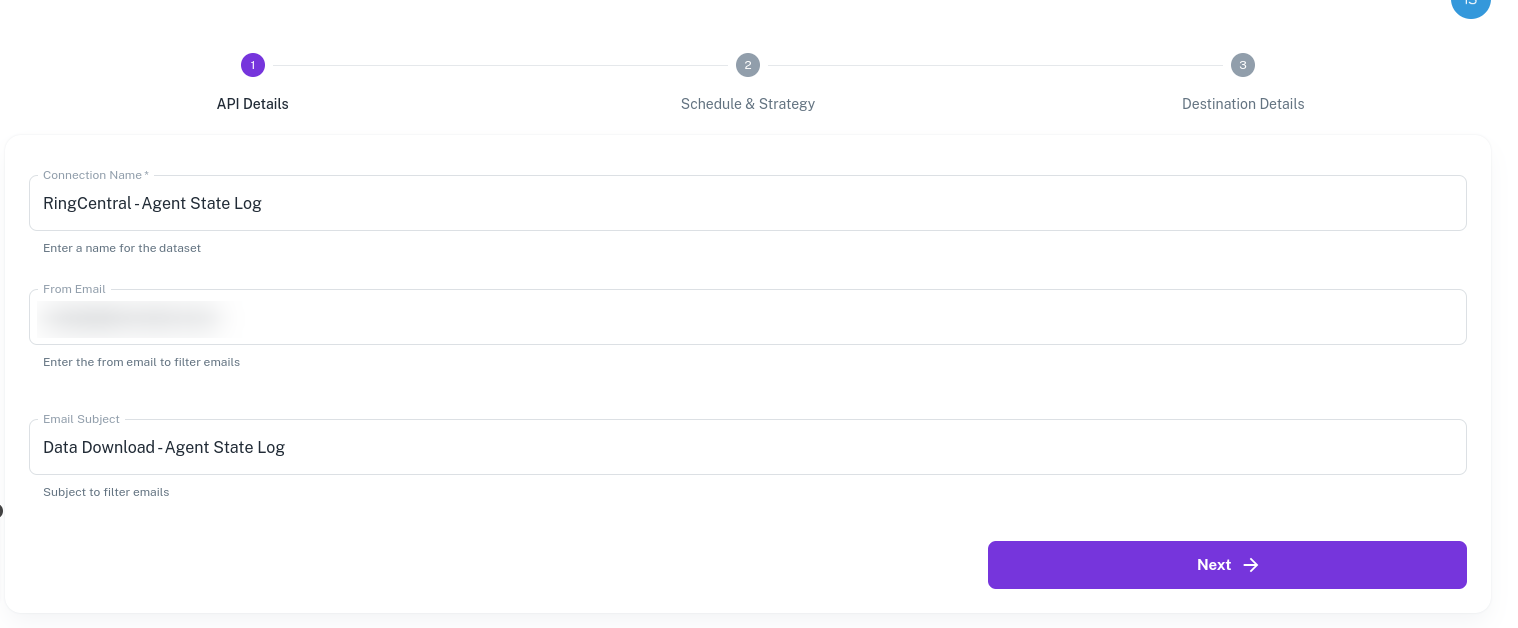
Email
ELT Data will look for the "From Email" and the subjects containing the string provided in "Email Subject" to filter out the relevant emails.
From these filtered emails, CSV files will be downloaded.
Only CSV and Excel attachments are supported by ELT Data. Excel files having formatting or macros are not supported.
API
The API Details tab has the following components:
Operation Id
Each API operation is defined using a unique id. Depending upon your dataset, select the operationId. The request and the response of the operation can be checked in the right half of the screen.
Pagination
If the pipeline supports pagination, select Yes and ELT Data will automatically loop through the pages in the application. The pagination support for the selected operation can be checked into the API Documentation listed on the right half of the screen.
Pipeline Variables
Pipeline variables are simple key value pairs. The values can be dynamic functions and are resolved at the run time. Pipeline variables are used for:
- Defining the dynamic inputs to be passed to the pipelines. For e.g. To run a pipeline with yesterday's date as an input, we will define a pipeline variable having the following value:
(datetime.date.today() - datetime.timedelta(days=1)).strftime('%m/%d/%Y')
- Defining the dynamic folder name pattern in the destination. You might want your blob/file folders to be named in a dynamic manner.
In the following image we have defined three pipeline variables which are used
- to provide dynamic start and end date to the API (start_date, end_date)
- to define a daily_folder_format
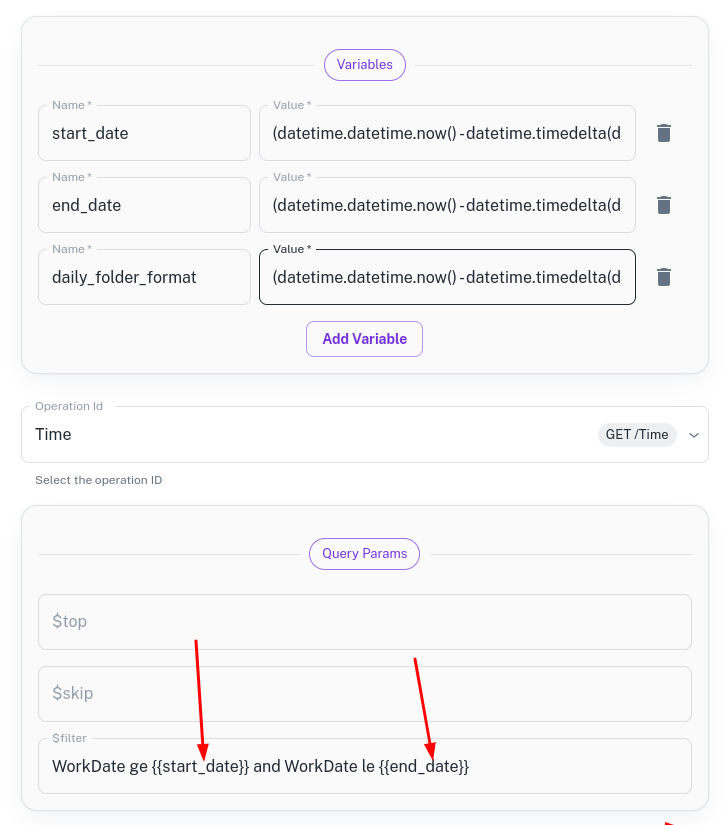
Supported Functions in Variables
The pipeline variables support only the datetime functions (Datetime Library documentation). Any other method resolves to an exception.
The return value of a datetime function should be a "string" type.
Using variables
The pipeline variables need to be enclosed in {{ }} brackets. These variables values are subsituted when the API runs. The pipeline variable function values are resolved during the run time.
While using the variable: You can append two or more variables. For e.g -
- {{startdate}}{{end_date}}
- daily_{{start_date}}
- employees{{start_date}}{{end_date}}_production
Examples
- Yesterday in mm/dd/yyyy format
Function - (datetime.date.today() - datetime.timedelta(days=1)).strftime('%m/%d/%Y')
Output - 11/19/2022
- Start of last month in dd-mm-yyyy format
Function - (datetime.date.today().replace(day=1) - datetime.timedelta(days=1)).replace(day=1).strftime('%d-%m-%Y')
Output - 01-10-2022
- End of last month in dd-mm-yyyy format
Function - (datetime.date.today().replace(day=1) - datetime.timedelta(days=1)).strftime('%d-%m-%Y')
Output - 31-10-2022
- Start of last week in dd-mm-yyyy HH:mm:ss format. Week starts on Monday and end on Sunday.
Function - (datetime.datetime.now() - datetime.timedelta(days=datetime.datetime.now().weekday() + 7)).replace(hour=0, minute=0, second=0, microsecond=0).strftime('%d-%m-%Y %H:%M:%S')
Output - '14-11-2022 00:00:00'
- End of last week in yyyy-mm-dd format
Function - (datetime.date.today() - datetime.timedelta(days=datetime.date.today().weekday() + 1)).strftime('%Y-%m-%d')
Output - '2022-11-20'
API Parameters
On selecting the OperationID, the available API parameters will be visible in the UI.
- The pagination parameters can be skipped unless you want to override those with a default value.
- Please provide any other parameter that you find necessary.
- The API parameters can be composed of Pipeline Variables and the values can be dynamic in nature. (ref the above image)
- The mandatory parameters are marked with * and the values need to be provided.
- The data fetch logic can be customized using the API parameters. For e.g - fetch data only for active=true employees or fetch data only for employees belonging to department id - 61.
- The API parameters are read from the API documentation.