Overview
In this article we look at all the stages of the data journey from raw input data to analysis and output. We will briefly explore the process flows at each stage.
We classify the data journey from source application to reporting output into the following stages:
- Data Ingestion - Get raaw data from the source application
- Data Transformation - Apply business logic / rules to convert the data into a form that supports business analysis
- Data Analysis / Reporting - Analyze and present the transformed data in a manner that it can be consumed by the end-user
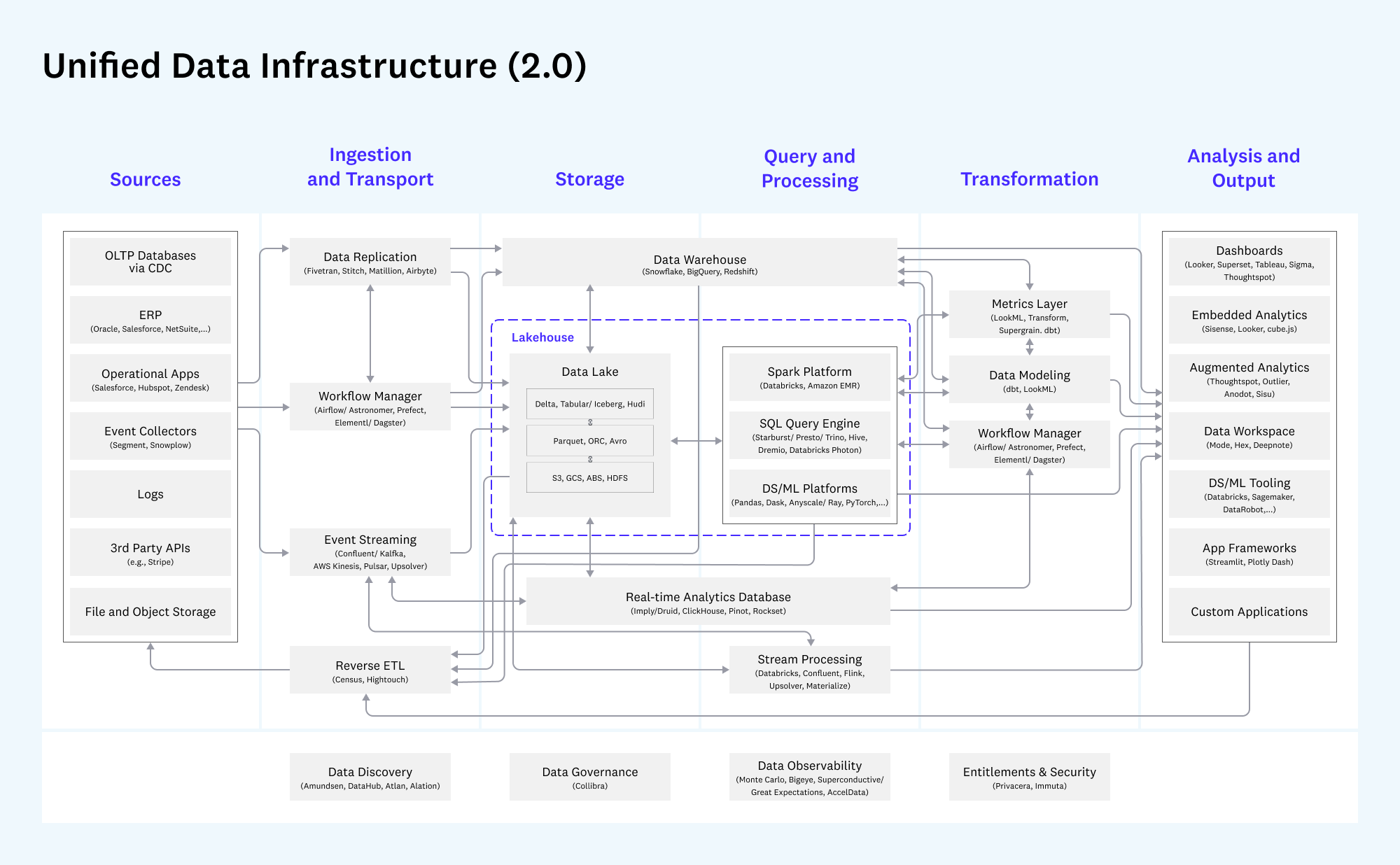
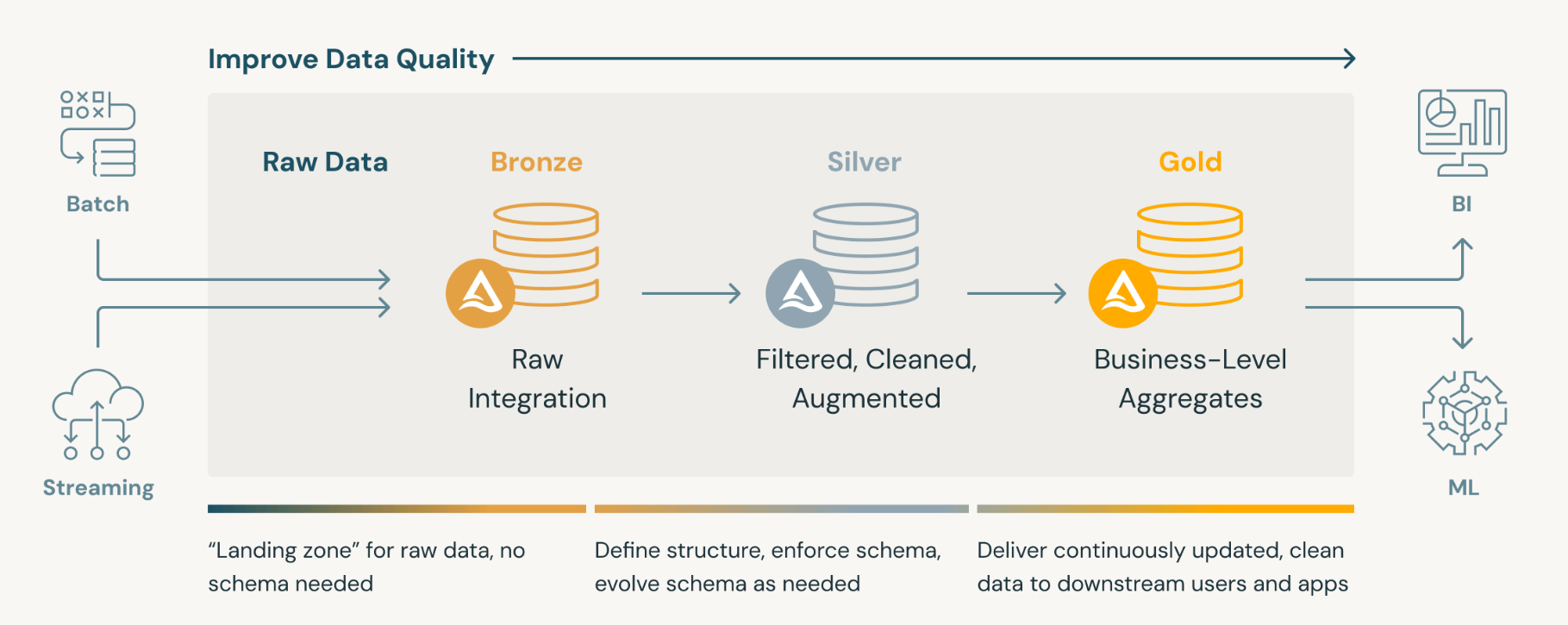
Source - https://a16z.com/emerging-architectures-for-modern-data-infrastructure/Data Ingestion
This stage deals with reading data from source applications and moving it to a central storage location. For example, ingest accounting data from NetSuite and store it in AWS S3. While doing this, ELT Data ensures that:
- Raw data is available in a consistent and reliable manner.
- A copy of deduped data is made in addition to the raw data.
- Input data meets basic quality parameters, e.g., no null records, fresh data check, primary key check.
- The data to be ingested is standardized and documented.
The above steps ensure input data quality and freshness and do not involve business logic. This stage is implemented by the data engineering team of ELT Data.
Popular data connectors include ELT Data, Fivetran and Airbyte.
In this stage we tranform the ingested raw data into business data. In this stage we focus on:
- Transforming the input data into the form required by the business.
- Defining relationships between the entities in the data warehouse.
- Writing data checks on business KPIs. E.g. sales this month > $10,000 OR NumofJobPerTechnician > 3
- Document and write the business transformed data to a warehouse table for further consumption.
While running data transformations, it is essential to ensure that the definitions of business KPIs are consistent across pipelines. For example, we may write one pipeline for sales by month and another for sales per employee per month. It is important that we keep the definition of sales consistent across the two transformation phases.
This stage is jointly implemented by the ELT Data engineering team (which provides the platform to run transformations) and the client's business analyst (who define the business rules and transformations).
Popular data transformation tools include DBT and Apache Spark.
Data Analysis / Reporting
The transformed data is finally used for business analysis and reporting. This stage involves presenting the business transfotmed data to different end-users in forms consumable by them. For example, financial reports for management often vary from the ones required for the operations team, though the underlying data for both reports is the same.
This stage is implemented by BI developers and consultants in the client organization.
Popular analytics and reporting tools include Power BI, Tableau, R and Python.
To ensure that data processes including the above three stages run in a consistent, predictable and manageable manner, ELT Data uses numerous supporting technologies and stages. In this section we briefly describe the key tools and the process stages in which they are used.
Workflow managers
Workflow managers are critical to managing complex data pipelines. Their primary functions include scheduling, automation, task dependency management, monitoring and logging, scalability, error handling and retries.
Popular workflow management tools include Airflow and Prefect.
Data quality checks
To make sure that our data pipelines are running and fetching data as expected, we can add on additional tooling to run data quality checks when it is fetched and transformed.
Popular data quality check tools include Great Expectations and AccelData.
Data discovery
As the data and the people working on it increase, keeping track of all the data assets becomes an issue. To keep our datasets fresh and documented, we can add tools to help us with the data organization.
Popular tools to aid discovery include Amundsen and Atlan.
Data governance
With increasing data volume and consumption, we may need to define access controls on the data assets. To help us with this, we can add tools around governance.
Based on the maturity and necessity of your organization, you can decide which of the supporting stages and tools to add.